들어가며
이 글은 관계형 데이터베이스에 대한 이해와 지식을 필요로 합니다. 또한, 모바일보단 PC 환경에서 읽기 편하도록 작성됐습니다.
보통 데이터베이스와 SQL을 배울 때 데이터베이스의 이론을 배우고 SQL 문법을 배우면서 실습합니다. 그런데 SQL문을 눈으로만 보면 이해하기 쉬운데 직접 작성하라고 하면 제대로 못하는 사람이 태반입니다. 관계대수는 테이블에서 원하는 결과를 얻기 위해 표현하는 방법을 배우는 학문입니다. 관계대수를 배워서 SQL Select문의 원리를 알면 SQL을 훨씬 깊게 이해하고 사용할 수 있습니다.
하지만 앞서 말했듯이 데이터베이스가 무엇인지. 그리고 관계형 데이터베이스가 무엇인지는 알고 이 글을 읽는 것을 권장합니다.
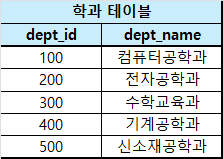
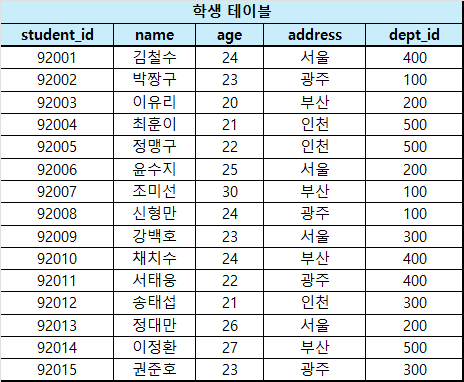
관계대수(Relational Algebra)
1. 정의
관계대수란 원하는 결과를 얻기 위해 수행해야 할 연산의 순서를 명시하는 절차적인 언어입니다. 쉽게 말하면 데이터에 대한 검색을 표현하기 위해 간결하고 형식적으로 만든 질의어입니다. 대수(Algebra)는 숫자 대신 수학적 기호와 연산자를 사용해 문제를 해결한다는 의미로 받아들이면 쉬울 것 같습니다.
2. 특징
1. 절차적인 언어(Procedural Language)
정의에서 언급했듯이 관계대수는 절차적인 언어입니다. 원하는 결과를 얻기 위해 수행해야 할 연산의 순서를 명시해야합니다.
절차적인 언어의 대표적인 예시는 Java, C, Python 등의 고급 언어들이 있습니다.
2. 피연산자와 결과
관계대수에선 피연산자와 결과가 모두 테이블입니다. 즉, 관계대수를 단순하게 특정 기능을 하는 함수라고 가정한다면 테이블을 입력하면 연산이 적용된 다른 테이블이 출력된다는 뜻입니다.
따라서 출력된 테이블은 다시 다른 연산의 입력이 될 수 있고, 해당 내용은 서브쿼리라는 이름으로 나중에 다룰 예정입니다.
3. 연산자
연산자의 종류는 2가지가 있습니다.
- 기본 관계 연산자(Relational operators) : 관계의 구조와 속성을 활용하여 데이터 가공
- SELECT
- PROJECT
- RENAME
- CARTESIAN PRODUCT
- 파생 연산자(Derivation operators) : 기본 연산자를 조합해서 연산
- JOIN
- DIVISION
- INTERSECTION
- 일반 집합 연산자(Set operators) : 튜플을 집합의 원소로 보고 포함 여부 기반으로 연산 수행
- UNION
- INTERSECTION
- RELATIVE COMPLEMENT
아래에서 각 연산자별 종류와 정의를 알아보겠습니다.
기본 관계 연산자
연산자를 설명하기 위해선 샘플 데이터가 필요합니다. 따라서 아래의 테이블을 바탕으로 설명하겠습니다.
필요에 따라 각 연산자에서 테이블 또는 행이 추가될 수 있습니다!


1. SELECT(선택)
선택은 단어 그대로 하나의 테이블에서 주어진 조건을 만족하는 레코드들을 선택하는 기능입니다.
선택 연산은 시그마($\sigma$)로 나타내고, 아래와 같이 사용합니다.
$$\large\sigma_{<조건식>}(<테이블\ 이름>)$$
- 테이블 이름은 조회하려는 테이블에 해당됩니다.
- 조건식은 비교연산자(<, >, <=, >=, <>) 또는 논리 연산자($\land$, $\lor$, NOT)를 입력할 수 있습니다.
예시 테이블로 SELECT 연산 사용 예시를 알아보겠습니다.
1. 주소가 서울인 학생
$$\large\sigma_{address = '서울'}(학생\ 테이블)$$
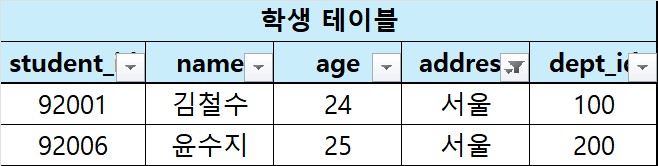
2. 나이가 25보다 많은 학생
$$\large\sigma_{age > 25}(학생\ 테이블)$$

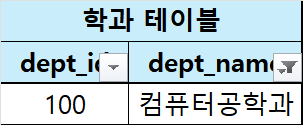
3. 학과 이름이 컴퓨터공학과인 학과
$$\large\sigma_{dept\_name = '컴퓨터공학과'}(학과\ 테이블)$$
4. 부산에 살면서 학과 나이가 25살 이하인 학생
이렇게 AND 조건으로 2개 이상이 주어진 경우 2가지 방법으로 나타낼 수 있습니다.
첫번째, 조건식에 논리 연산자를 사용하는 방식입니다.
$$\large\sigma_{address = '부산'\ \land\ age <= 25}(학생\ 테이블)$$
두번째, 선택 연산을 중첩해서 사용하는 것입니다.
$$\large\sigma_{age <= 25}(\sigma_{address = '서울'}(학생\ 테이블))$$
AND 조건만 중첩해서 나타낼 수 있기 때문에 선택 연산을 중첩했을 때는 교환 법칙이 성립합니다.
$$\large\sigma_{조건식1}(\sigma_{조건식2}(학생\ 테이블))=\sigma_{조건식2}(\sigma_{조건식1}(학생\ 테이블)) $$
두 가지 표현 모두 결과는 아래와 같습니다.

5. 나이가 23살 이상이거나 주소가 인천인 학생
이렇게 OR 조건으로 2개 이상이 주어진 경우엔 중첩은 불가능하고 하나의 조건식 내에서만 표현할 수 있습니다.
나중에 합집합 연산을 배우면 표현 방법이 하나 추가됩니다!
$$\large\sigma_{address = '인천'\ \lor\ age >= 23}(학생\ 테이블)$$
결과는 다들 예상될테니 생략하겠습니다.
*중요. 값이 NULL일 때 처리
만약 학생 테이블에서 이름이 조미선인 학생의 나이가 null로 저장되어 있다면 2번 예시는 어떤 결과가 출력될까요?
값이 null인 경우 시스템은 비교불가로 판정해서 항상 조건식의 결과가 FALSE가 됩니다. 따라서 null은 절대 선택되지 않습니다.
2. PROJECT(추출)
추출은 테이블에서 사용자가 원하는 필드만을 결과로 출력하는 연산입니다.
선택 연산에서 우린 조건을 만족하는 레코드의 모든 필드가 출력되는 것을 봤습니다. 하지만 추출에선 원하는 필드만 선택해서 사용자에게 보여줍니다.
만약, 추출된 값들 중 중복이 존재한다면 중복을 제거해서 보여줍니다.
추출 연산은 파이($\pi$)로 나타내고, 아래와 같이 사용합니다.
$$\large\pi_{<필드리스트>}(<테이블\ 이름>)$$
- 테이블 이름에 연산의 대상이 되는 테이블을 작성합니다.
- 필드리스트에 추출하고자 하는 필드들의 리스트를 콤마로 구분해서 작성합니다.
예시 테이블로 PROJECT 연산 예시를 살펴보겠습니다.
1. 학생의 학번과 이름만 추출
$$\large\pi_{student\_id,\ name}(학생\ 테이블)$$

2. 학번, 이름, 나이를 추출하고 학번, 나이를 다시 추출
일반적으로 추출 연산끼리 중첩해서 사용할 일은 거의 없지만 추출 연산에서 중요한 내용이 있어서 아래처럼 예시를 만들었습니다.
$$ \large\pi_{student\_id,\ name}(\pi_{student\_id,\ name,\ age}(학생\ 테이블))$$
위는 문법적으로 문제가 없는 질의입니다.
하지만 내부 추출 연산의 필드리스트에서 name을 빼면 어떻게 될까요?
내부 추출 결과가 외부 추출 연산의 입력이 되는데 외부 추출 결과에선 name 필드를 출력하려고 하고 있습니다. 하지만 외부 추출의 입력 테이블에 name 필드가 없어서 문법 오류가 발생하게 됩니다.
이를 통해 우리는 아래와 같이 결론을 내릴 수 있습니다.
$$\large <outer\ field\ list>\ \subseteq\ <inner\ field\ list>$$
즉, 외부 필드리스트는 내부 필드리스트의 진부분집합이어야 합니다.
3. 나이가 23살 이상인 학생의 이름만 추출
2번처럼 추출을 중첩하는게 아닌 3번처럼 선택과 추출을 중첩해서 사용하는게 일반적입니다.
추출의 피연산자에 선택 연산의 결과 테이블을 넣으면 됩니다.
$$\large\pi_{name}(\sigma_{age >= 23}(학생\ 테이블))$$

이렇게 선택과 추출을 다양하게 중첩해서 원하는 결과를 절차적으로 얻을 수 있습니다.
3. RENAME(재명명)
재명명은 테이블에 이름을 부여하거나 변경하는 연산입니다.
실제 데이터베이스의 값을 변경하는 것이 아닌 현재 쿼리 내부에서만 사용하는 이름으로 변경하는 것입니다.
재명명 연산은 로우($\rho$)로 나타내고, 아래와 같이 총 3가지 방식으로 사용합니다.
첫번째, 테이블의 이름만 변경합니다.
$$\large\rho_{<테이블명2>}(<테이블명1>)$$
- 테이블명1을 테이블명2로 변경
두번째, 테이블의 필드명만 변경합니다.
$$\large \rho_{(<변경된 필드리스트>)}(<테이블명>)$$
- 괄호가 필드리스트를 감싸고 있다는 점에 주의
세번째, 테이블명과 필드명 모두 변경합니다.
$$\large \rho_{<테이블명2>(<변경된 필드리스트>)}(<테이블명1>)$$
- 테이블명1을 테이블명2로 바꿈
- 필드리스트의 이름도 변경
선택과 추출 연산을 중첩해서 사용할 때 재명명 연산을 사용해 가독성을 높일 수 있습니다.
아래는 선택, 추출, 재명명을 종합적으로 사용한 예시입니다.
1. 나이가 23살 이하인 학생을 선택해서 결과 테이블 이름을 "young"로 바꾸고 학번과 이름만 추출
$$\large \pi_{young.stu\_id,\ young.name}\ (\rho_{young}\ (\sigma_{age <= 23}(학생\ 테이블)))$$
- 다소 복잡해보일 수 있지만 내부 연산부터 하나씩 해석해보면
- 학생 테이블에서 23살 이하인 학생 선택
- 선택된 학생들의 테이블 이름을 young으로 변경
- young으로 변경된 테이블에서 학번과 이름만 추출
결과는 아래와 같습니다.

4. CARTESIAN PRODUCT(카테시안 곱)
카테시안 곱은 두 테이블의 각 행의 모든 조합으로 레코드를 생성합니다.
카테시안 곱은 곱하기($\times$) 기호로 나타내고, 아래와 같이 표현합니다.
$$\large \text{<테이블1>}\ \times\ \text{<테이블2>}$$
아래의 2개의 수정된 테이블을 보겠습니다.
기존 테이블에서 빠른 이해를 위해 레코드의 수를 줄였습니다.
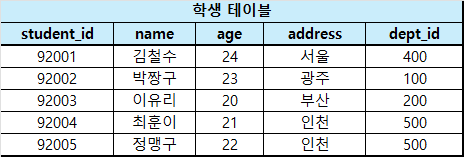
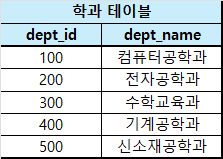
필드 이름이 같든 말든 필드 개수가 같든 말든 카테시안 곱 $\text{학생 테이블} \times\ \text{학과 테이블}$을 하면 아래의 표처럼 각 행에 대해 모든 조합의 레코드를 생성합니다.

카테시안 곱을 하는 방법은 어렵지 않습니다. 하지만 카테시안 곱을 왜 하는건지는 아직 감이 안 올 것 같습니다.
카테시안 곱은 다음과 같은 상황에서 주로 사용합니다.
- 두 테이블의 모든 레코드 조합을 알고 싶을 때
- 두 테이블을 JOIN 연산하기 위한 준비
입력 레코드의 개수가 늘어나면 $row_1*row_2$의 속도로 출력 레코드의 개수가 늘어나고, 이 중 대부분이 의미 없는 레코드입니다.
그럼 의미있는 레코드는 뭘까요?
다시 카테시안 곱 결과 테이블을 보겠습니다.

어떤 레코드에 노란색 배경을 칠했는지 감이 오나요?
dept_id가 같은 레코드에 대해서 노란색으로 칠했습니다. 하나의 레코드에서 dept_id가 같다는 건 dept_name 값까지 관련이 있다는 뜻입니다. 하지만 모든 하얀색 레코드들은 dept_id가 다르므로 아무 의미가 없는 레코드가 되어버립니다. 예를 들어, 1행의 김철수는 수학교육과 학생인데 컴퓨터공학과랑 연관시켜 봤자 알 수 있는 정보가 없다는 뜻입니다.
카테시안 곱은 대부분 JOIN 연산을 위해 쓰이고, JOIN 연산을 위해 카테시안 곱의 개념을 알아야합니다. 카테시안 곱은 이쯤하고 바로 JOIN 연산으로 넘어가겠습니다.
파생 연산자(JOIN / DIVISION)
파생 연산자로는 JOIN과 DIVISION이 있습니다. JOIN은 또 다양한 종류가 존재합니다. 이번 섹션에선 JOIN과 DIVISION의 의미 및 표현 방법을 살펴보겠습니다.
파생 연산자를 설명하기 전에 역시 예제 테이블을 보고 가겠습니다.
앞선 테이블에서 레코드를 더 추가했습니다. 학생 테이블의 dept_id는 학과 테이블의 PK인 dept_id를 참조하고 있습니다.
1. $\theta$-JOIN
조인이 처음이라면 위의 4. CARTESIAN PRODUCT부터 읽고 와주세요!
조인 중에 가장 처음 소개할 조인은 바로 $\theta-join$입니다.
JOIN은 결국 카테시안 곱의 결과에 특정 조건이 걸린 꼴입니다. 카테시안 곱이 의미 없는 데이터까지 모두 생성했다면 JOIN은 그중 필요한 결과만 얻기 위해 조건을 추가해준 연산입니다.
조인의 종류는 다양한데 이번 글에선
- $\theta$-JOIN
- NATURAL JOIN
- OUTER JOIN
로 크게 나눠서 설명하겠습니다.
$\theta$-JOIN은 정확하게는 그냥 조인이지만 나중에 나올 다른 JOIN들과 구분하기 위해 세타 조인이라고도 부릅니다.
세타 조인 연산은 카테시안 곱의 결과에 조건식을 만족하는 레코드만 선택하는 연산입니다.
세타 조인은 나비 넥타이 모양($\bowtie$)를 기호로 나타내고, 아래와 같이 표현합니다.
$$\large \text{<테이블1>} \bowtie_{\text{<조건식>}}\ \text{<테이블2>}$$
- 카테시안 곱의 결과에 조건식에 해당하는 결과만 선택하겠다는 의미
이제 학생 테이블, 학과 테이블과 함께 세타 조인을 알아보겠습니다.
1. 각 학생의 이름과 소속한 학과의 이름을 추출
2개의 테이블에 있는 레코드끼리 연관지어야하므로 우선 카테시안 곱을 만들어야합니다. 카테시안 곱을 만들고 학생 테이블의 dept_id와 학과 테이블의 dept_id가 똑같은 레코드만 의미 있다고 조건을 지정합니다.
그러면 아래와 같이 작성할 수 있습니다.
$$\large \text{학생 테이블}\ \bowtie_{학생\ 테이블.dept\_id = 학과\ 테이블.dept\_id}\ \text{학과 테이블}$$
그럼 아래와 같은 결과를 얻을 수 있습니다.
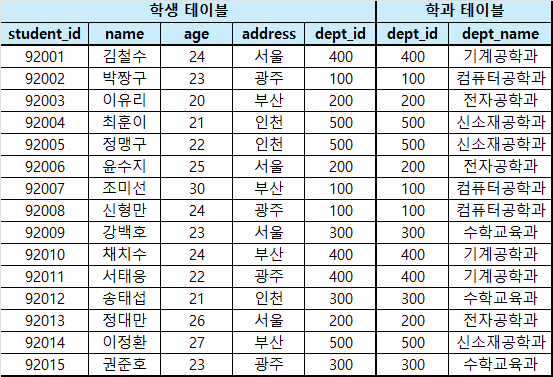
EQUI-JOIN
이렇게 $\theta$-JOIN의 조건식이 동등 비교(=)일 때를 EQUI-JOIN(동등 조인)이라고도 부릅니다.
2. NATURAL JOIN
자연 조인이라고 부르는 이 조인은 EQUI-JOIN을 단순하게 표현하기 위한 조인입니다.
두 테이블을 자연 조인 연산하면 이름이 같은 컬럼을 자동으로 동등 비교합니다. 그리고 이름이 같은 컬럼은 중복되지 않게 한 번만 출력합니다. 만약 이름이 같은 컬럼이 여러 개라면 모든 컬럼이 일치하는 경우만 선택합니다.
$\theta$-JOIN의 표현식에서 조건식만 없애면 자연 조인을 의미하게 됩니다.
$$ \large \text{<테이블1>} \bowtie\ \text{<테이블2>} $$
만약 공통되는 컬럼이 하나도 없다면 카테시안 프로덕트와 동일한 결과를 출력합니다.
$\theta$-JOIN에서 다뤘던 1번 예시를 다시 보겠습니다.
기존의 표현식 $\text{학생 테이블}\ \bowtie_{학생\ 테이블.dept\_id = 학과\ 테이블.dept\_id}\ \text{학과 테이블}$에서 조건식을 없앤
$$\large \text{학생 테이블}\ \bowtie\ \text{학과 테이블}$$
이 바로 자연 조인이고, 위의 예제 테이블에서 동일한 결과를 출력합니다.
3. OUTER JOIN
OUTER JOIN. 즉 외부조인은 조인 조건에 만족되지 않은 레코드까지 검색 결과에 포함시키기 위한 연산입니다. 조인 조건에 만족하지 않는데 강제로 레코드를 결합해서 보여주려면 분명 어떤 값을 할당해야합니다. 그래서 서로 매치(Match)되지 않는 필드에 대해서는 NULL 값을 할당합니다.
외부 조인의 종류는 총 3가지 있습니다.
- LEFT OUTER JOIN
- RIGHT OUTER JOIN
- FULL OUTER JOIN
각각의 외부 조인은 아래에서 하나씩 설명할 예정이고, 외부 조인을 설명하기 위한 새로운 테이블 2개를 보겠습니다.
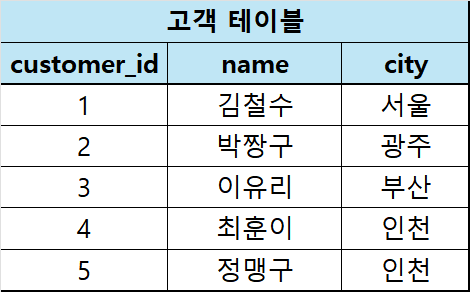

특정 쇼핑몰이 있다고 가정하고, 고객 테이블에 가입된 고객들의 정보가 저장되어있습니다.
그리고 주문 테이블에는 모든 고객의 주문 정보가 저장되어있습니다. 주문 테이블의 customer_id는 고객 테이블의 PK를 참조합니다.
1. LEFT OUTER JOIN
LEFT OUTER JOIN은 왼쪽 외부 조인이라고 부릅니다. LEFT OUTER JOIN만 알면 RIGHT OUTER JOIN도 바로 알 수 있습니다.
왼쪽 외부 조인은 $\Large⟕$로 나타내고, 아래처럼 표현합니다.
$$\large \text{테이블1}\ ⟕_{\text{<조건식>}}\ \text{테이블2}$$
- 테이블1을 기준으로 테이블2와 조건을 만족하는 레코드를 붙임
- 단, 동등 조인이더라도 같은 컬럼은 2번 보임
외부 조인 최대한 쉽게 설명하기
외부 조인이 와닿지 않는 분을 위해 최대한 쉽게 설명해보겠습니다. 테이블 A와 B가 있습니다.
그리고 A라는 테이블을 기준으로 잡으면 A의 관점에서 테이블 B는 외부 테이블이 됩니다. 그런데 테이블 A에게 외부의 테이블 B를 연관시켜서 A의 결과를 보고 싶은 상황입니다. 그럼 결과적으로 A테이블의 모든 레코드는 출력되고, 테이블 B의 레코드는 A와 연관되는 레코드에만 붙어서 출력됩니다. 그런데 테이블 A의 레코드 하나와 테이블 B의 레코드 여러 개가 연관될 수 있습니다. 이럴땐 A는 B의 정보를 모두 가져오기 위해 본인의 레코드를 필요한만큼 복제합니다. 그리고 테이블 A에는 존재하지만 B와는 연관되지 않는 레코드의 컬럼 값은 전부 NULL로 저장합니다.
1. 고객 테이블에 주문 결과를 왼쪽 외부 조인
$$\large \text{고객 테이블}\ ⟕_{고객테이블.customer\_id=주문테이블.customer\_id}\ \text{주문 테이블}$$

아래 두가지 버전의 설명을 순서대로 읽어주세요.
이해하기 쉬운 설명
만약 자연 조인이었다면 마지막 2행은 출력되지 않았겠지만 외부 조인이므로 고객 테이블의 모든 레코드가 출력됐습니다.
또 고객 아이디가 1인 김철수는 주문 테이블과 매칭해서 보려고 하니까 1대2 관계입니다. 그래서 A의 레코드 하나를 복제해서 주문 테이블의 두 레코드와 매칭해서 보여줍니다.
정확한 설명
모든 조인 연산은 조건식으로 걸러지기 전에 카테시안 곱부터 수행한다고 했습니다. 두 테이블의 모든 조합에 대해 레코드가 생성되면 왼쪽 외부 조인은 먼저 동등 비교 등의 조건식이 성립하는 레코드는 전부 선택합니다.
그리고 왼쪽 테이블의 하나의 레코드에 대해 조건식이 성립하는 레코드가 오른쪽 테이블에 하나도 없다면 NULL값으로 왼쪽 테이블과 매칭해서 보여줍니다.
2. 주문 테이블에 고객을 왼쪽 외부 조인
$$\large \text{고객 테이블}\ ⟕_{주문테이블.customer\_id=고객테이블.customer\_id}\ \text{주문 테이블}$$

주문 테이블을 기준으로 왼쪽 외부 조인을 하면 결과는 자연 조인과 동일합니다. 일반적으로 고객 테이블에 존재하지 않는 사람이 주문을 해서 주문 테이블에 데이터가 저장될 일이 없기 때문입니다.
제가 예제 테이블을 실무 기준으로 생성했기 때문에 자연 조인과 동일한 결과가 나타났지만 충분히 다양한 상황에선 매칭되지 않는 레코드로 인해 NULL 값이 저장되는 경우가 있습니다.
2. RIGHT OUTER JOIN
RIGHT OUTER JOIN은 오른쪽 외부 조인이라고 부르고, $\Large ⟖$ 기호로 나타냅니다.
오른쪽 외부 조인은 왼쪽 외부 조인과 완전히 똑같은데 순서만 다릅니다. A ⟕ B라는 왼쪽 외부 조인과 B ⟖ A라는 오른쪽 외부 조인은 완전히 동일한 결과를 보여줍니다.(다만 테이블의 컬럼 순서는 바뀝니다)
따라서 LEFT OUTER JOIN의 관계대수식을 다시 가져오면 $\text{고객 테이블}\ ⟕_{고객테이블.customer\_id=주문테이블.customer\_id}\ \text{주문 테이블}$인데 동일하게 오른쪽 외부 조인으로 표현해보면 아래와 같습니다.
$\large \text{주문 테이블}\ ⟖_{고객테이블.customer\_id=주문테이블.customer\_id}\ \text{고객 테이블}$
결과 또한 순서가 바뀌어서 아래처럼 출력됩니다.

3. FULL OUTER JOIN
FULL OUTER JOIN은 완전 외부 조인이라고 부르고, ⟗ 기호로 나타냅니다.
완전 외부 조인은 A ⟕ B와 A ⟖ B 결과의 합집합과 같습니다.
따라서 수식으로 나타내면 아래와 같습니다.
$$\large \text{A ⟗ B}=\text{A ⟕ B} \cup \text{A ⟖ B}$$
마찬가지로 예제 테이블을 완전 외부 조인하면 결과는 아래와 같습니다.

A ⟗ B는 결국 A ⟕ B와 A ⟖ B 결과의 합집합인데 A ⟕ B와 A ⟖ B의 합집합은 $A ⟖ B \subseteq A ⟕ B $이므로 A ⟕ B와 동일했습니다. 따라서 위와 같은 결과가 출력됩니다.
2. DIVISION
DIVISION은 나눗셈 연산입니다.
나눗셈 연산은 $\div$로 나타내고, 아래와 같이 표현합니다.
$$\large \text{<테이블1>}\ \div\ \text{<테이블2>}$$
- 테이블2의 모든 행의 값을 가지고 있는 테이블1의 행을 찾아주는 연산
- 테이블1은 테이블2의 모든 속성을 포함하고 있어야 함
- 컬럼명이 같을 필요는 없지만 도메인과 속성이 같아야 함
나눗셈 연산도 글로는 이해가 어려워서 예시를 보겠습니다.
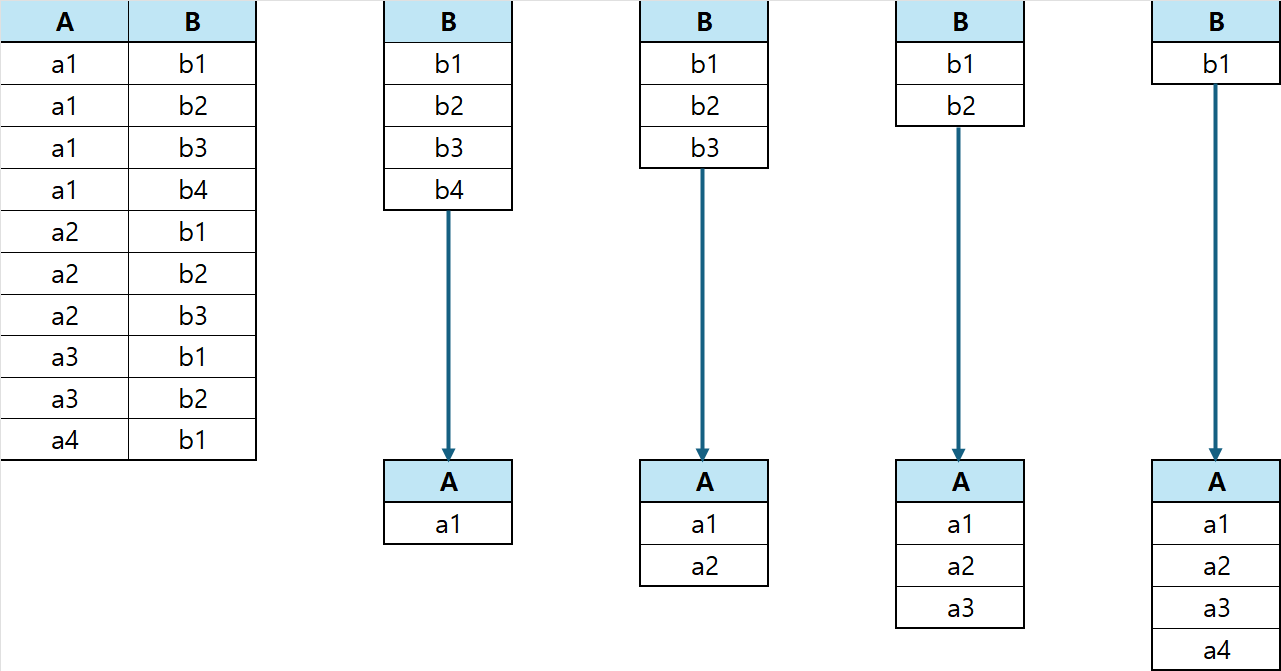
좌측 상단이 테이블1에 해당됩니다. 그리고 우측 상단의 4개의 테이블이 테이블2가 되고 테이블1을 나눕니다. 각 결과가 화살표로 연결되어있습니다.
각각 테이블2가 포함한 모든 레코드 값을 포함하는 테이블1의 레코드를 찾습니다.
나눗셈 연산은 많이 쓰이지 않으므로 가볍게 "이런게 있다~"로 넘어가도 무관합니다.
3. INTERSECTION
교집합 연산은 파생 연산자임과 동시에 일반 집합 연산자입니다. 따라서 아래의 일반 집합 연산자에서 다루겠습니다.
일반 집합 연산자
집합 연산자는 피연산자인 테이블을 집합으로 생각하고 다루는 연산입니다.
기본 관계 연산자와는 다른 점이 두 집합을 합치거나 빼는 등의 연산을 수행하므로 항상 피연산자가 2개라는 것입니다.
집합 연산을 위해선 피연산자들의 스키마가 동일해야합니다. 즉 컬럼 이름, 컬럼 개수, 컬럼 순서, 컬럼 간 데이터 타입 호환 여부를 만족해야 집합 연산할 수 있습니다.
아래는 집합 연산자를 효과적으로 설명하기 위해 만든 테이블입니다.



학생과 교수의 dept_id는 각각 소속된 학과입니다.
1. UNION(합집합)
합집합은 두 테이블의 레코드를 합치되 중복을 제거하는 연산입니다.
합집합 연산은 $\cup$으로 나타내고, 두 테이블에 대한 합집합 연산은 아래처럼 표현합니다.
$$\large \pi_{<동일한\ 필드리스트>}(<테이블1>)\ \cup\ \pi_{<동일한\ 필드리스트>}(<테이블2>) $$
1. 학생 테이블과 교수 테이블 합집합
위의 예시 테이블에서 학생과 교수 테이블은 첫번째 컬럼을 제외하고 스키마가 동일합니다. 따라서 재명명 연산으로 통일시켜주고 합집합 연산을 진행하면 됩니다.
$$\large \pi_{id,\ name,\ age,\ address,\ dept\_{id}(학생\ 테이블)}\ \cup\ \pi_{id,\ name,\ age,\ address,\ dept\_{id}(교수\ 테이블)}$$
결과는 아래와 같습니다.

2. INTERSECTION(교집합)
교집합은 두 테이블 모두 가지고 있는 레코드만 걸러내는 연산입니다.
교집합은 앞서 배운 JOIN 연산 때문에 잘 사용하진 않지만 이론은 알고 있어야합니다.
교집합 연산은 $\cap$으로 나타내고, 두 테이블에 대한 교집합 연산은 아래처럼 표현합니다.
$$\large \pi_{\text{<동일한 필드리스트>}}(\text{<테이블1>})\ \cap\ \pi_{\text{<동일한 필드리스트>}}(\text{<테이블2>})$$
아래는 사용 예시입니다. 결과는 충분히 예상할 수 있으므로 생략하겠습니다.
1. 교수가 한 명 이상 배정된 학과 번호 조회
교수가 한 명도 배정되지 않았다면 교수 테이블의 dept_id에 값이 등장하지 않았다는 의미입니다.
$$\large \pi_{dept\_id}(교수\ 테이블)\ \cap\ \pi_{dept\_id}(학과\ 테이블)$$
학과 테이블의 dept_id를 하나의 테이블로 만들고, 교수 테이블의 dept_id를 하나의 테이블로 만들어서 교집합하면 교수가 배정된 학과들을 조회할 수 있습니다.
TIP!
여기서 짚고 넘어가야할 내용이 있습니다.
교수 테이블의 dept_id는 학과 테이블의 PK를 참조하고 있는 FK입니다.
따라서 교수 테이블의 dept_id를 집합으로 표현한 것을 PSet, 학과 테이블의 dept_id를 집합으로 표현한 것을 DSet이라고 하면 $PSet\ \subseteq\ DSet$을 항상 만족합니다.
따라서 $PSet\ \cap\ DSet = PSet$을 항상 만족합니다.
현실적으로 FK와 PK의 교집합을 하는 경우가 많으므로 굳이 교집합을 구하지 않고, FK 컬럼의 집합을 구하는 것이 성능상 유리합니다.(Null 같은 예외 상황 제외)
따라서 위의 1번과 같은 케이스에서도 그냥 $\pi_{dept\_id}(교수\ 테이블)\ \cap\ \pi_{dept\_id}(학과\ 테이블) = \pi_{dept\_id}(교수\ 테이블)$입니다.
2. 나이가 같은 교수와 학생 조회
$$\large \pi_{age}(\text{교수 테이블}) \cap \pi_{age}(\text{학생 테이블})$$
마찬가지로 교수의 나이와 학생의 나이를 추출해서 교집합 연산하면 됩니다.
Intersection vs Join
질의에 따라 `INTERSECT`와 `JOIN`으로 동일한 결과를 얻을 수 있는 경우가 있습니다.
(예: 특정 조건을 모두 만족하는 사용자 찾기)
관계대수 이론에서는 JOIN을 카테시안 곱(Cartesian Product) 후 필터링하는 방식으로 설명하기 때문에, JOIN이 비효율적이라고 생각할 수 있습니다.
하지만 실제 DBMS는 이론처럼 모든 경우의 수를 생성하지 않습니다. 대신 다음과 같은 최적화된 알고리즘을 사용합니다.
- Index Nested Loop Join
- Hash Join
- Merge Join
이러한 방식으로 필요한 데이터만 효율적으로 결합합니다.
또한 `INTERSECT` 역시 내부적으로 정렬(Sort) 또는 해시(Hash) 연산과 중복 제거 과정이 포함되기 때문에 항상 더 빠르다고 볼 수는 없습니다.
따라서 SQL 작성 시 중요한 것은 JOIN과 INTERSECT 중 하나를 일반적으로 더 우수하다고 판단하는 것이 아니라, 데이터 크기, 인덱스 여부, 실행 계획 (EXPLAIN) 등을 기반으로 적절한 방식을 선택하는 것입니다.
3. RELATIVE COMPLEMENT(차집합)
테이블 A에서 테이블 B를 빼는 차집합 연산은 테이블 A에서 A와 B의 교집합을 제거하는 연산입니다.
차집합 연산은 마이너스(-) 기호로 나타내고, 두 테이블에 대한 교집합 연산은 아래처럼 표현합니다.
$$\large \pi_{\text{<동일한 필드리스트>}}(\text{<테이블1>}) - \pi_{\text{<동일한 필드리스트>}}(\text{<테이블2>})$$
아래는 사용 예시입니다.
1. 교수가 한 명도 배정되지 않은 학과 번호 조회
앞에서 교수가 한 명 이상 배정된 학과 번호를 조회하는 관계대수식은 $\pi_{\text{dept_id}}(\text{교수 테이블})$이었습니다.
교수가 한 명도 배정되지 않은 학과 번호를 찾으려면 학과 테이블에서 학과 테이블과 교수 테이블의 교집합을 제거하면 됩니다! 따라서 아래와 같이 작성할 수 있습니다.
$$ \large \pi_{\text{dept_id}}(\text{학과 테이블}) \ -\ \pi_{\text{dept_id}}(\text{교수 테이블}) $$
그럼 결과적으로 수학교육과인 300번만 남습니다.
지정 연산(Assignment Operators)
마지막으로 지정 연산에 대해 알아보겠습니다.
지정 연산은 특정 분류에 속하지 않고, 독립적인 연산입니다.
관계대수식을 작성하다보면 길어지면서 가독성이 떨어지게 됩니다. 그래서 질의를 여러 개로 분리하고, 중간 결과에 임시 이름을 부여해서 간단하게 만듭니다.
지정 연산은 $\leftarrow$를 기호로 사용합니다.
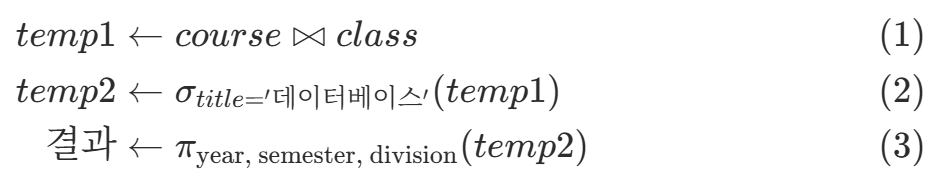
.
.
.
마치며
이미 SQLD에 합격했지만 관계대수를 배우니까 확실히 SELECT문을 더 잘 쓸 수 있을 것 같습니다. 관계대수를 실제로 사용할 일은 거의 없지만 알고 모르고의 차이는 SQL을 배우면서 클 것 같습니다.
데이터베이스의 첫 글로 관계대수를 다뤘고, 이제 시간날 때마다 SQL을 본격적으로 다뤄보겠습니다!
궁금한 점이나 잘못된 점은 댓글로 피드배 부탁드립니다! 😊